Open models: The lens in China, adoption trends, and new usage patterns
What’s on my mind
What’s on my mind
Part 1: A phase transition for open models
2025: Everyone built a reasoning model.
2025: Everyone built a reasoning model.
2025: Everyone built a reasoning model.
2025: Everyone built a reasoning model.
2025: Everyone built a reasoning model.
2025: Everyone built a reasoning model.
Part 2: measuring the open language model ecosystem
The ATOM Project
What have we done for ATOM?
What have we done for ATOM?
Cumulative downloads by region (China’s lead)
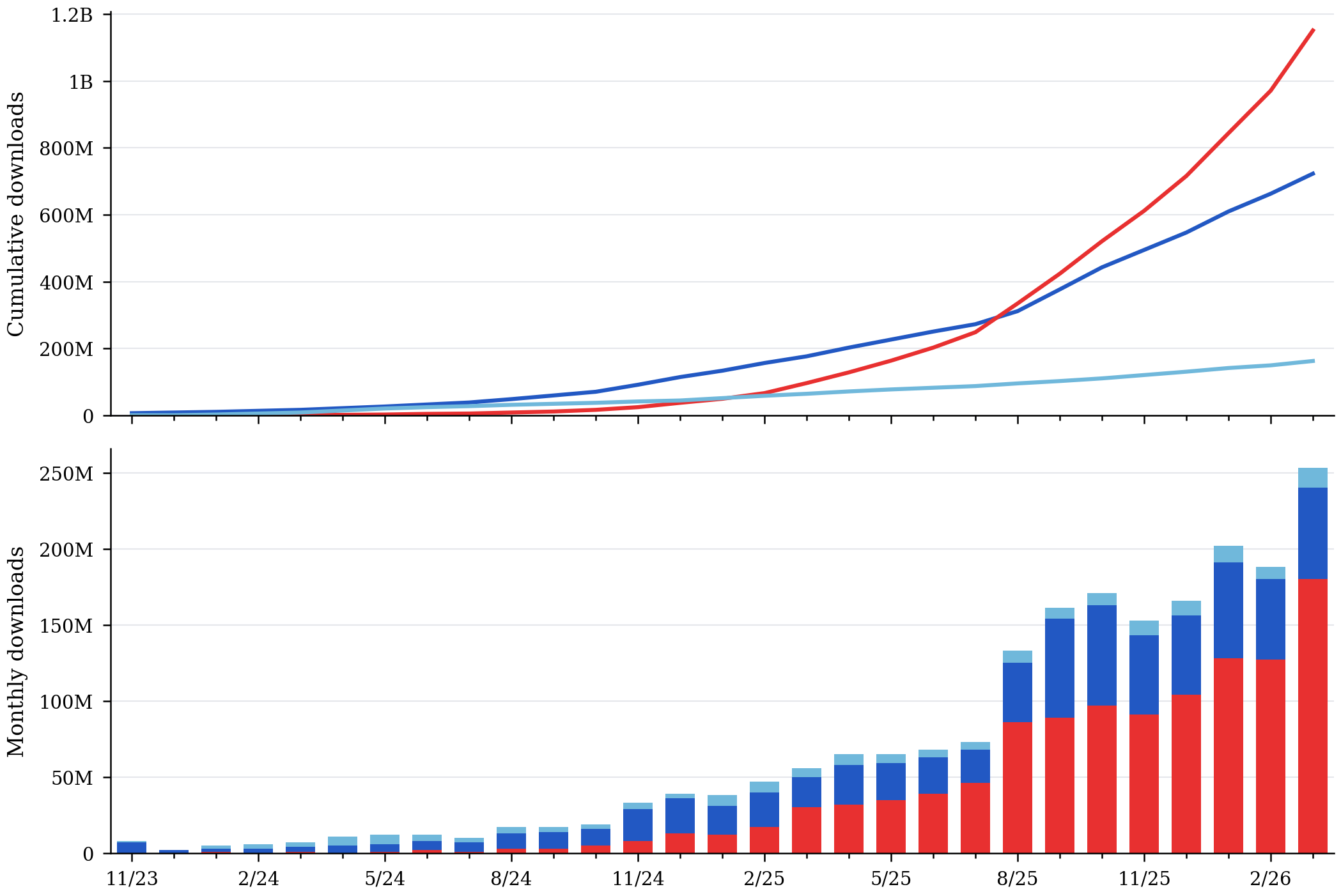
Region
USA
China
EU
Cumulative downloads by organization (Qwen’s lead)
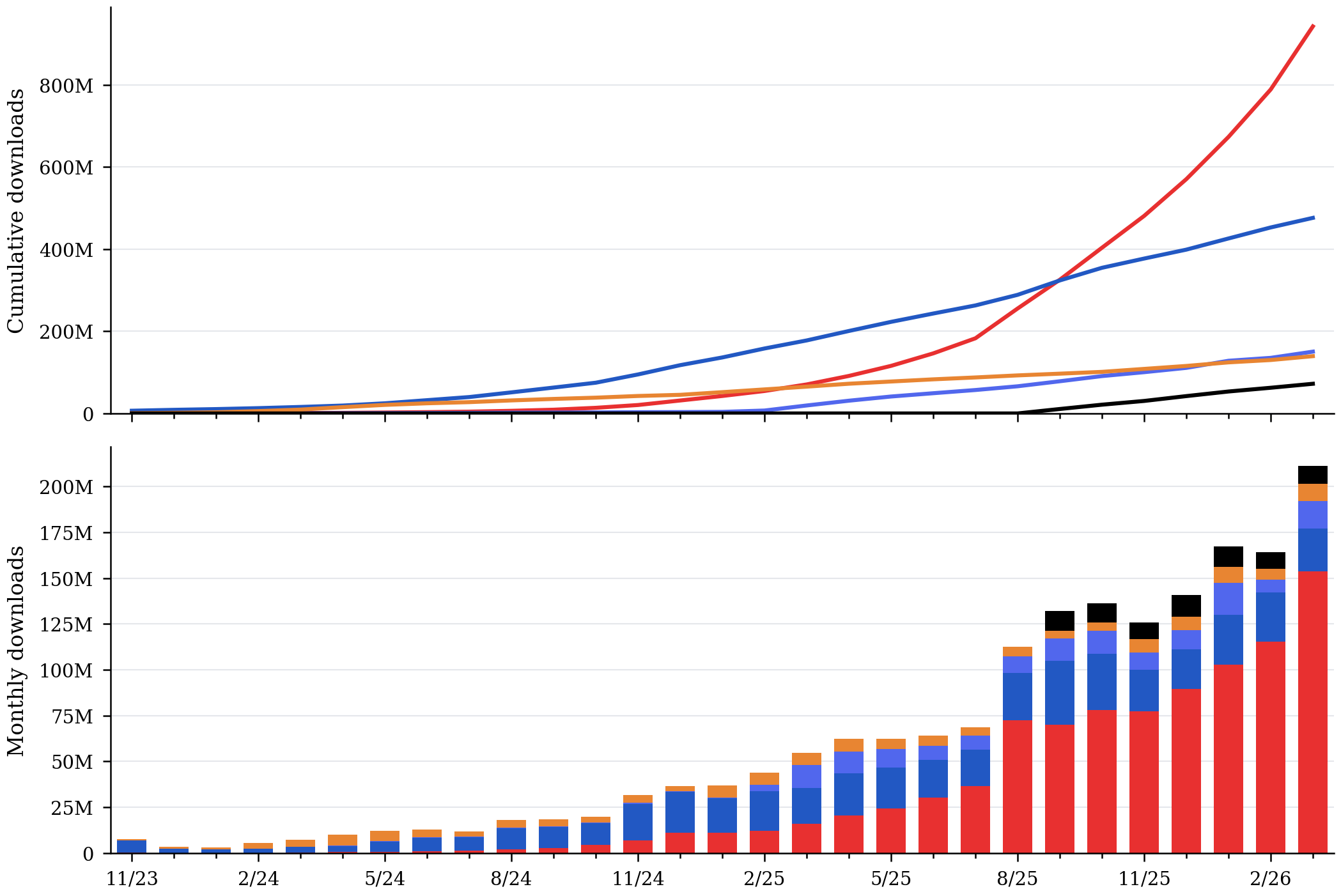
Family
Qwen
Meta
DeepSeek
Mistral
OpenAI
China’s continued lead in fine-tuning derivative models
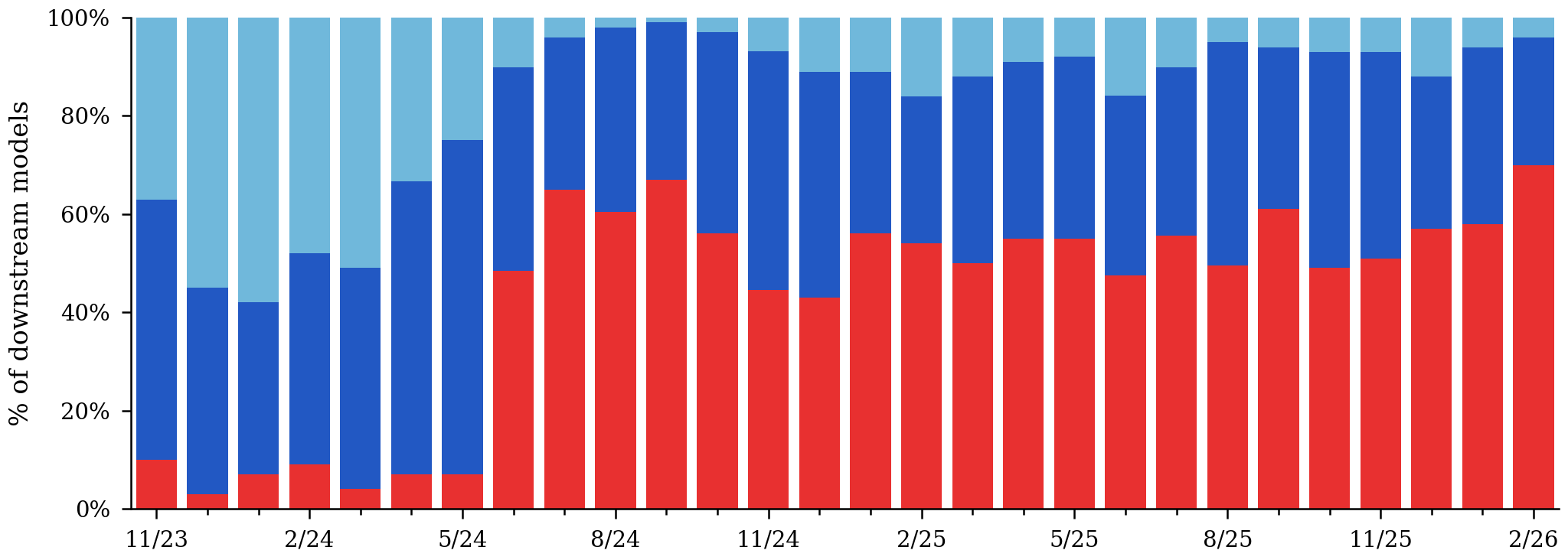
All models with >5 downloads, derived from likes of Qwen, Llama, Mistral, etc. models. China 10% → 70% of derivatives. Europe 58% → 4%. Derivative share leads downloads as a forward signal.
Region
China
USA
Europe
Inference token share from OpenRouter
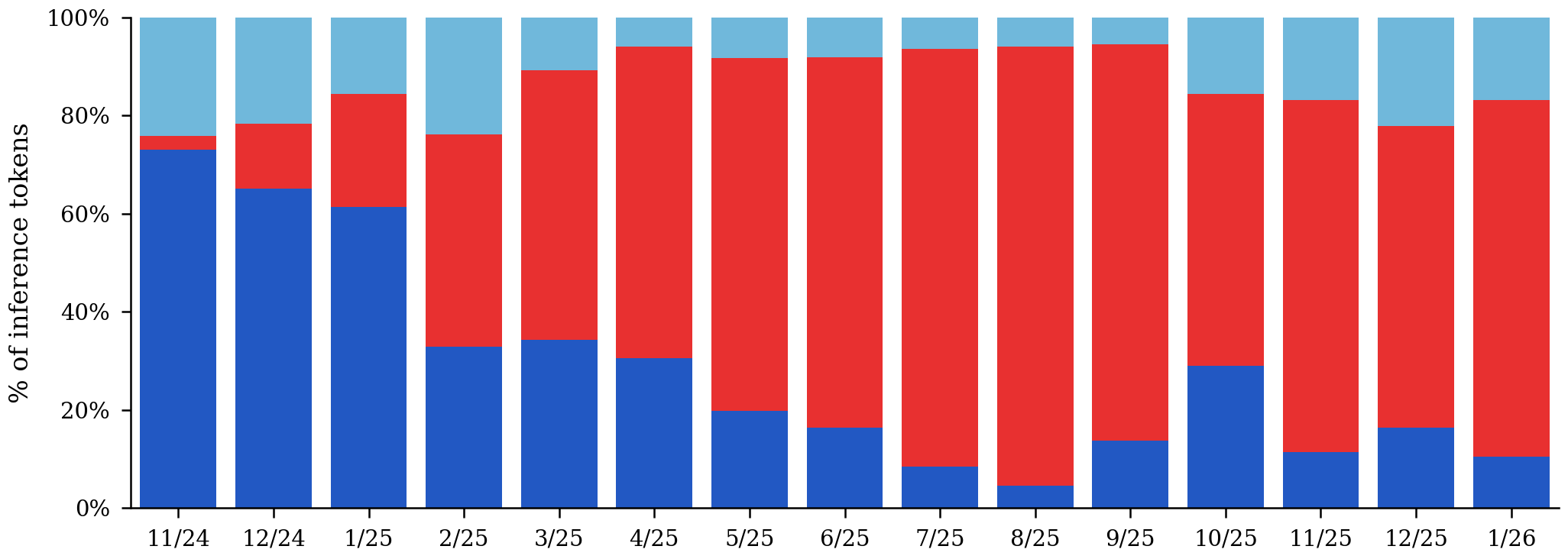
Tracking top 10 open models per month, and their share of inference on OpenRouter. China 2.8% (Nov '24) → 72.7% (Jan '26).
Region
USA
China
EU
Performance — Arena Elo
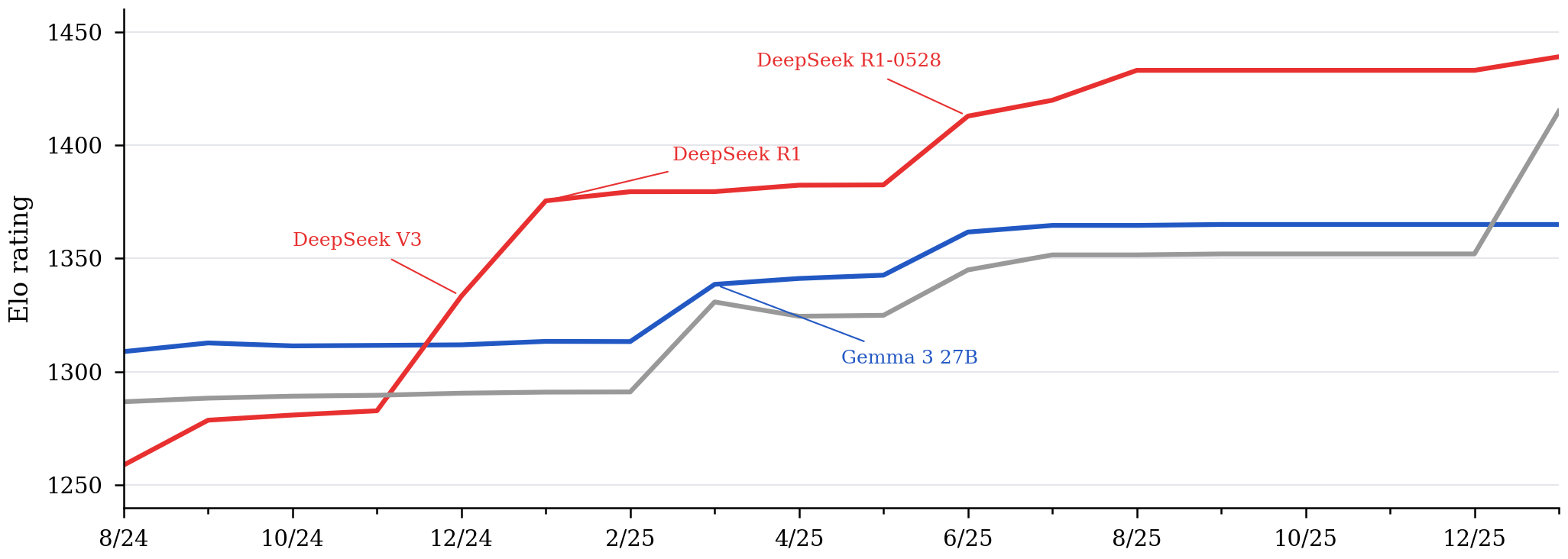
Region
USA
China
Other
Performance — Artificial Analysis Intelligence Index
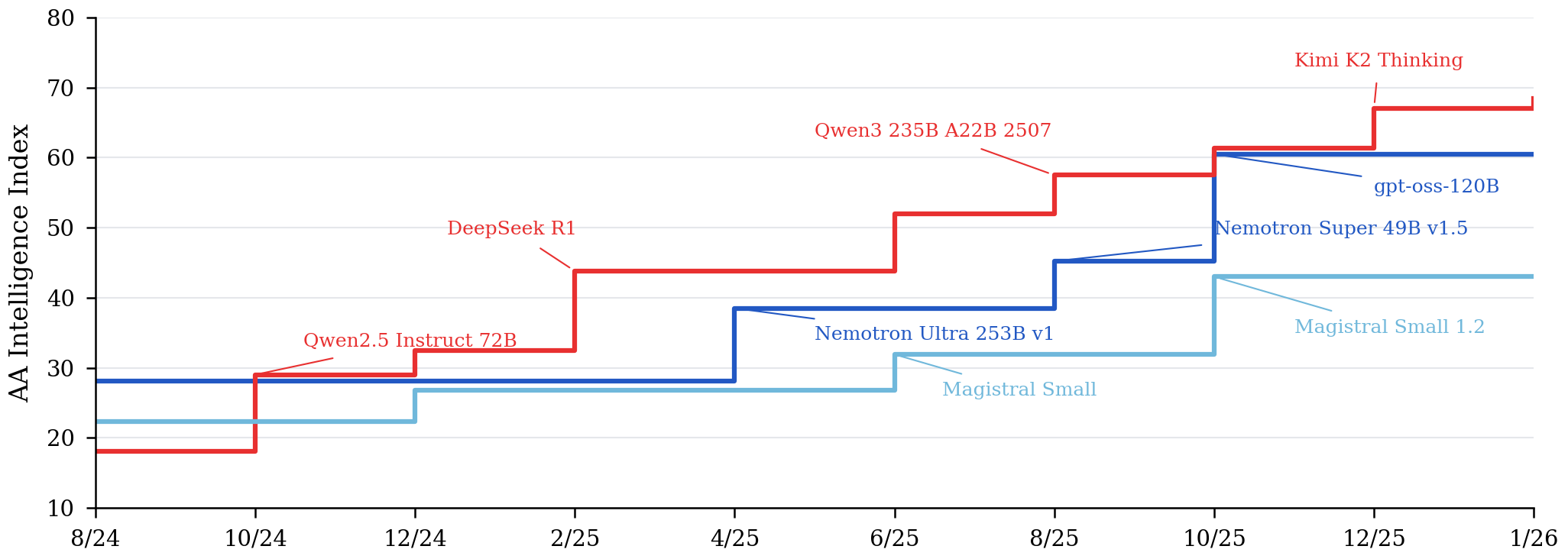
Region
USA
China
EU
Qwen is on top of the adoption world
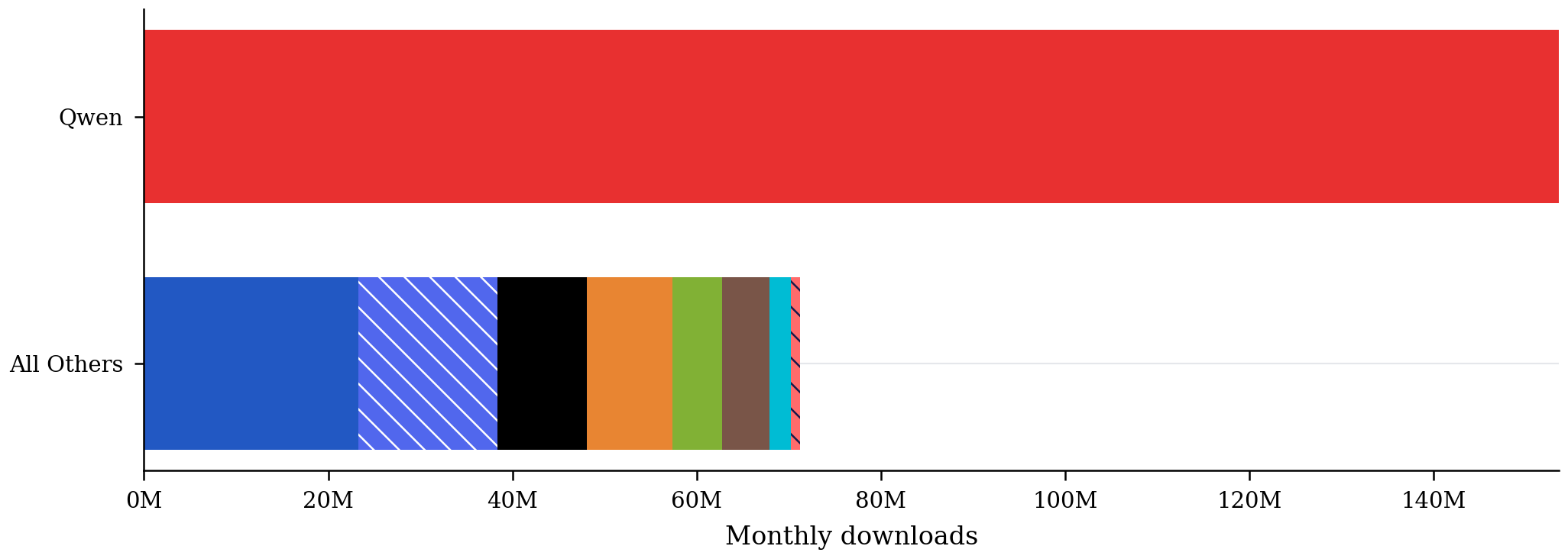
153.6M in February for Qwen vs 71.2M for the next eight orgs combined.
Org
Qwen
Meta
DeepSeek
OpenAI
Mistral
NVIDIA
01.AI
Moonshot AI
MiniMax
The Qwen3 small-model effect
The top 5 small Qwen3 models dominate monthly download numbers (again, February).
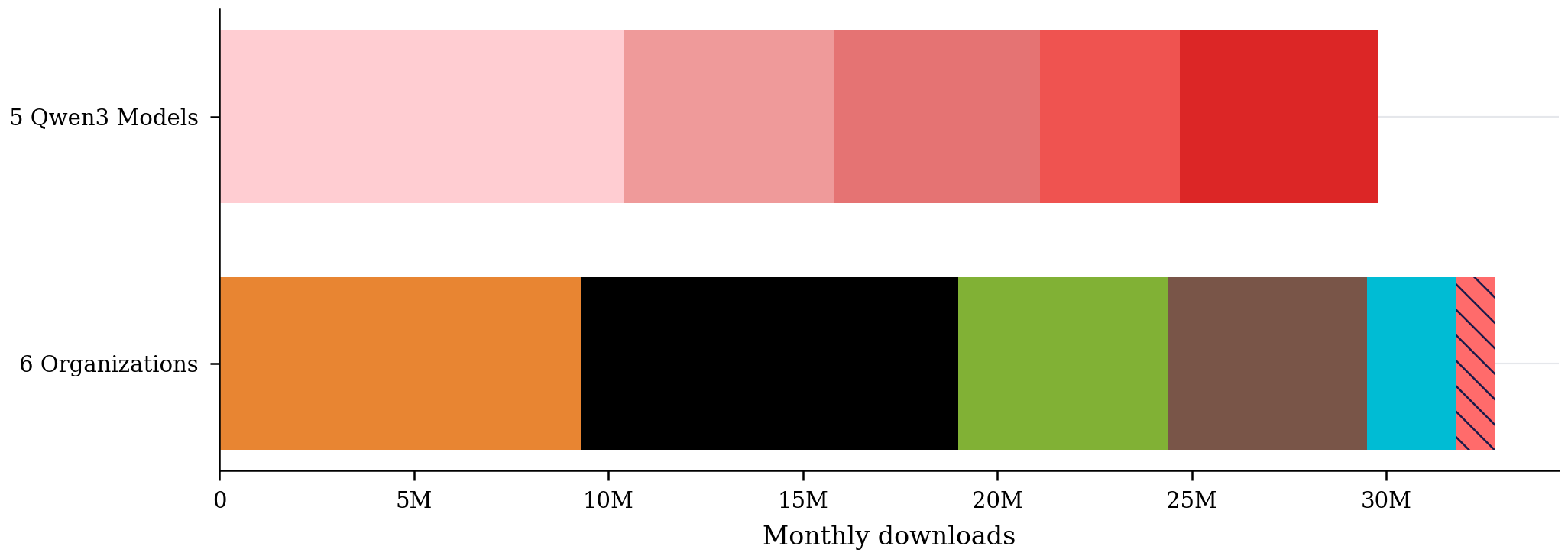
Segments
Qwen3 0.6B
Qwen3 1.7B
Qwen3 8B
4B Instruct
4B Thinking
Qwen3 4B
Mistral
OpenAI
NVIDIA
01.AI
Moonshot AI
MiniMax
Qwen’s one adoption weakness is large models
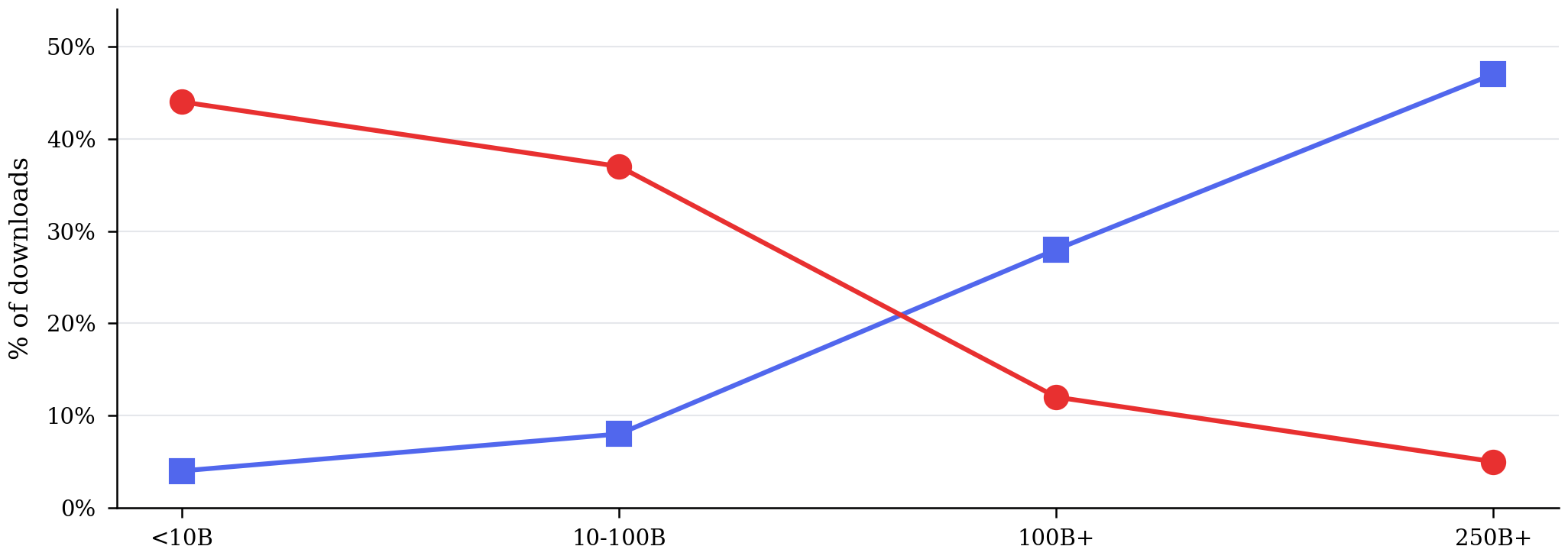
DeepSeek = 47% of 250B+ downloads. Two coexisting strategies: Qwen breadth across sizes, DeepSeek flagship at the frontier.
Org
DeepSeek
Qwen
Part 3: China’s AI labs’ own perspectives on open models
My China trip
Cultural commonalities across the labs
Cultural commonalities across the labs
Observations of the AI industry
My thoughts on distillation
My thoughts on the open-closed performance gap
Conclusions
References
Extra slides follow
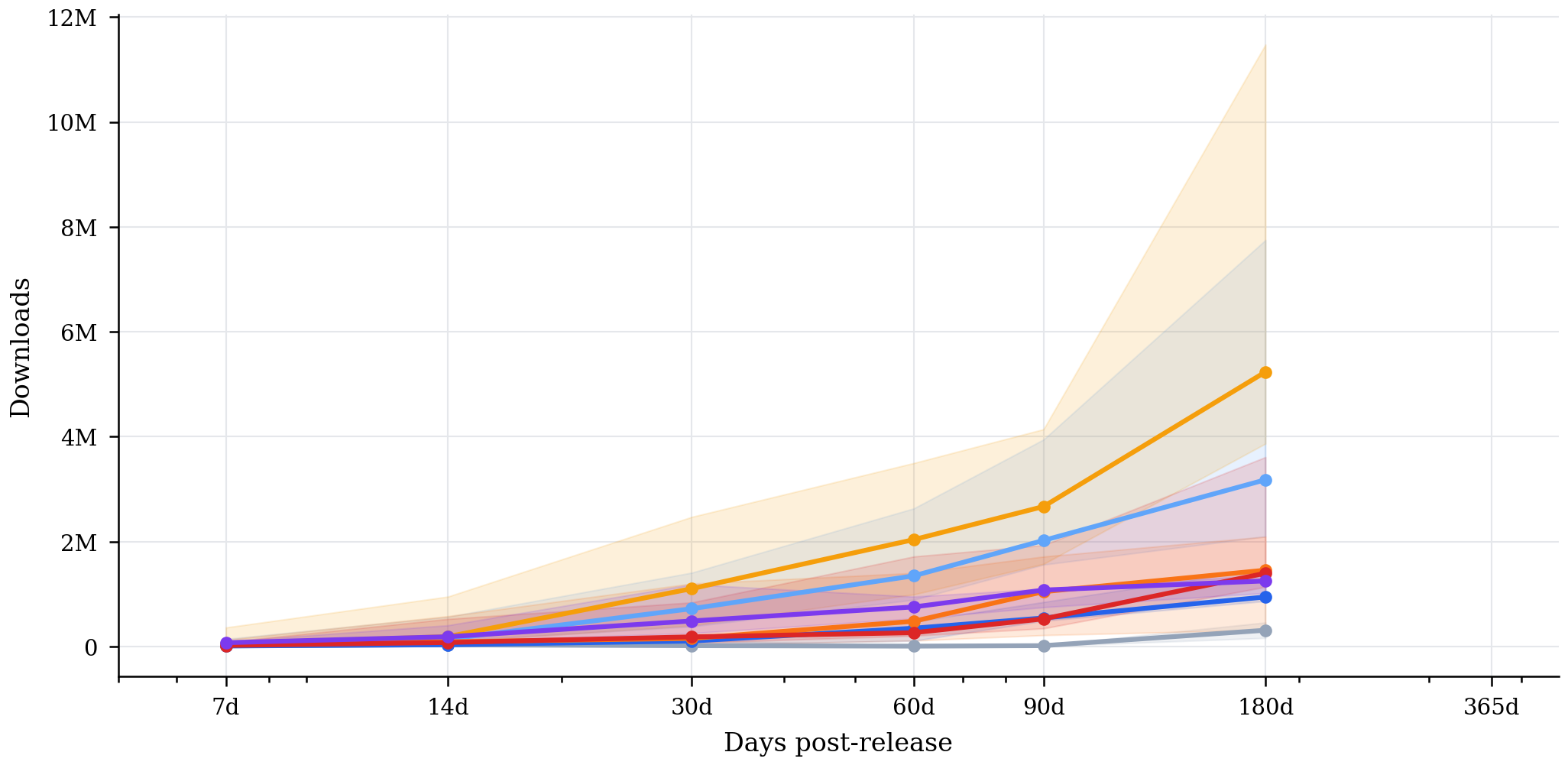
RAM overview
RAM size bins
Size bucket
<1B
1-5B
7-9B
10-50B
50-100B
100-250B
250B+
line = median, band = p25-p75
RAM case studies
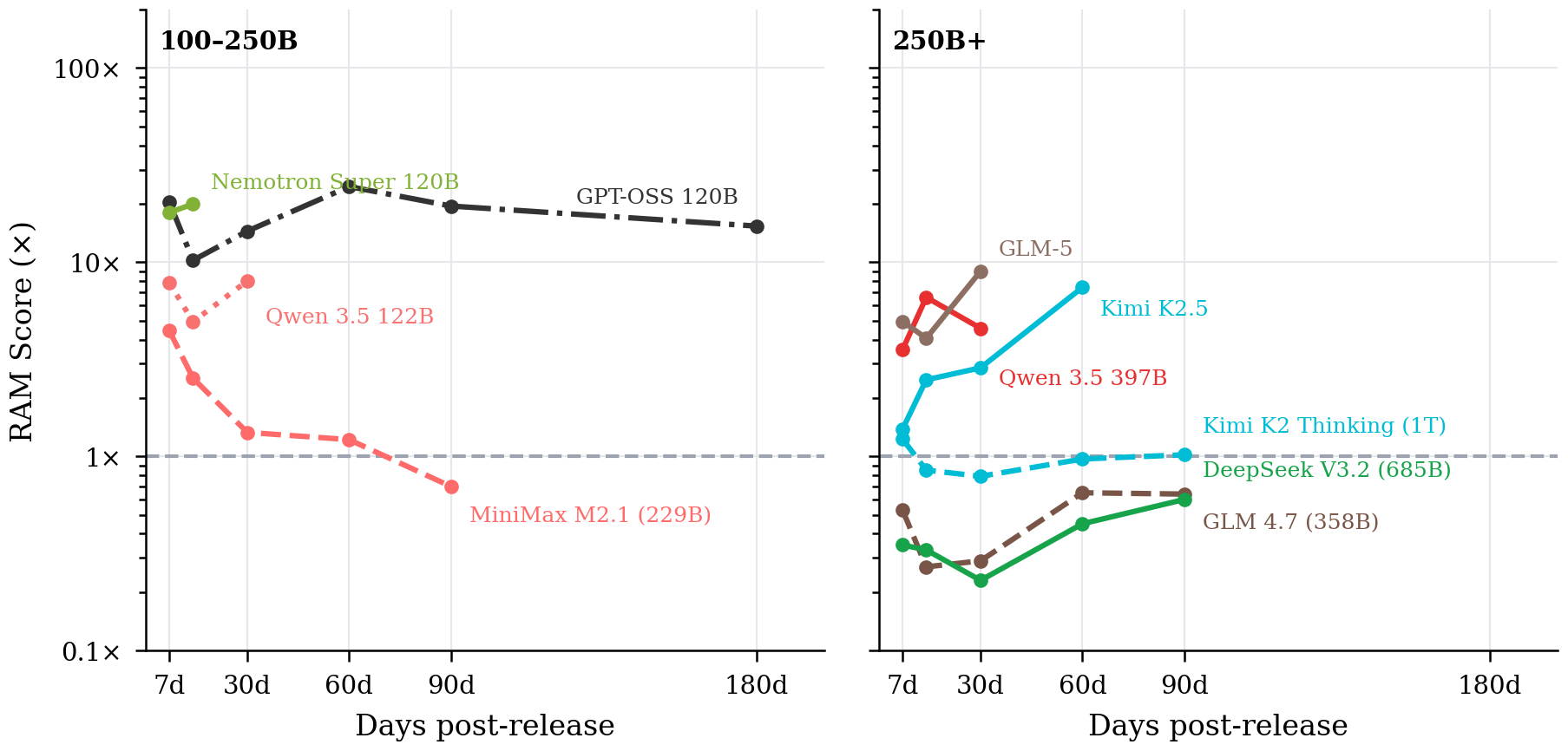
Elements
labeled model trajectory
bucket median
left = 100-250B, right = 250B+
The American comeback?
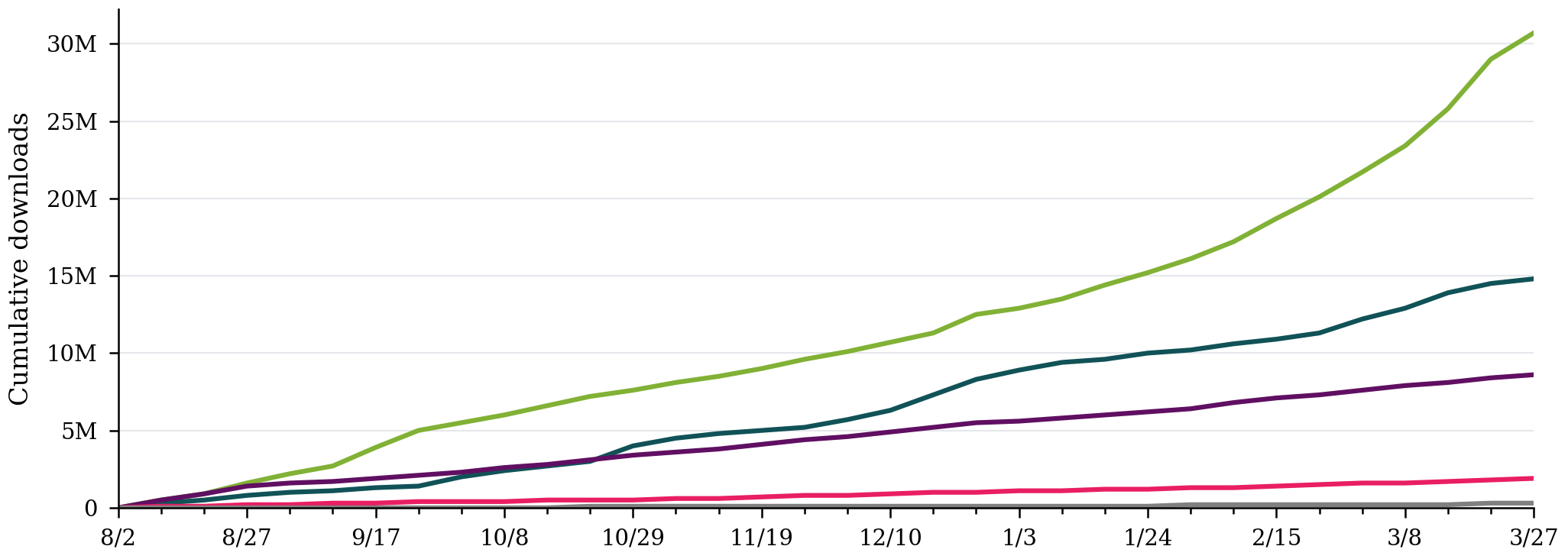
GPT-OSS surpassing Mistral’s entire legacy portfolio. Nemotron’s ramp accelerating. Disruption is still possible.
Org
NVIDIA
Allen AI
IBM
AI21
Arcee